4 CPU虚拟化
4 CPU虚拟化
CPU虚拟化的技术目标就是产生一种存在无限多CPU的假象,这一目标主要通过时分共享(time sharing)实现。时分共享中的执行单位/调度单位就是进程。
(摘自MIT6.S081课)进程本身不是CPU,但是它们对应了CPU,它们使得你可以在CPU上运行计算任务。应用程序不能直接与CPU交互,只能与进程交互。操作系统内核会完成不同进程在CPU上的切换。所以,操作系统不是直接将CPU提供给应用程序,而是向应用程序提供“进程”,进程抽象了CPU,这样操作系统才能在多个应用程序之间复用一个或者多个CPU。
4.1 抽象:进程
进程指正在执行中的程序。操作系统使用进程列表记录当前的所有进程,进程列表由一系列进程控制块(PCB)组成(可以是数组或者双向链表等),进程的相关属性信息存储在进程控制块中,典型的进程属性信息包括:PID、状态、地址空间、硬件状态等。
- PID:进程的标识符,除了本身的PID以外,还应当记录parent PID。
- State:进程状态,例如ready(可以被调度)、running(正在执行)、waiting(因需要某种资源而等待)。
- Address space:进程的虚拟内存地址空间,包括主存(用户空间、内核空间)、寄存器(一般寄存器、控制寄存器)、外部设备(文件、socket、其他内存映射IO设备)等。将在第5节中详细描述。
- Hardware state:特指关键的寄存器如PC、SP等。
一个进程可以被创建(从程序创建并转为ready状态)和销毁(被terminate)。一个进程只能被另一个进程所创建。Linux中关于进程的API有:
- fork():复制出与当前进程一样的子进程,当前进程与子进程同时运行(按照调度规则),根据fork对当前进程与子进程的返回值不一样,(按照返回值作为判断依据的分支)执行不同的程序片段直到返回。
- wait():在使用了fork已经创建了子进程的情况下, 当前进程执行到wait处时等待子进程返回后才接着运行。
- exec()/execve():使用exec后,新的进程将直接替代当前进程(而不是创建子进程的并结束当前进程),新进程覆盖原来的内存空间(例如数据段、代码段、栈等)并接着运行直到返回。
- kill():向进程发送一个信号(虽然名字是kill但不一定是结束进程)。
本人绘制了一些示意图说明它们的区别与联系: 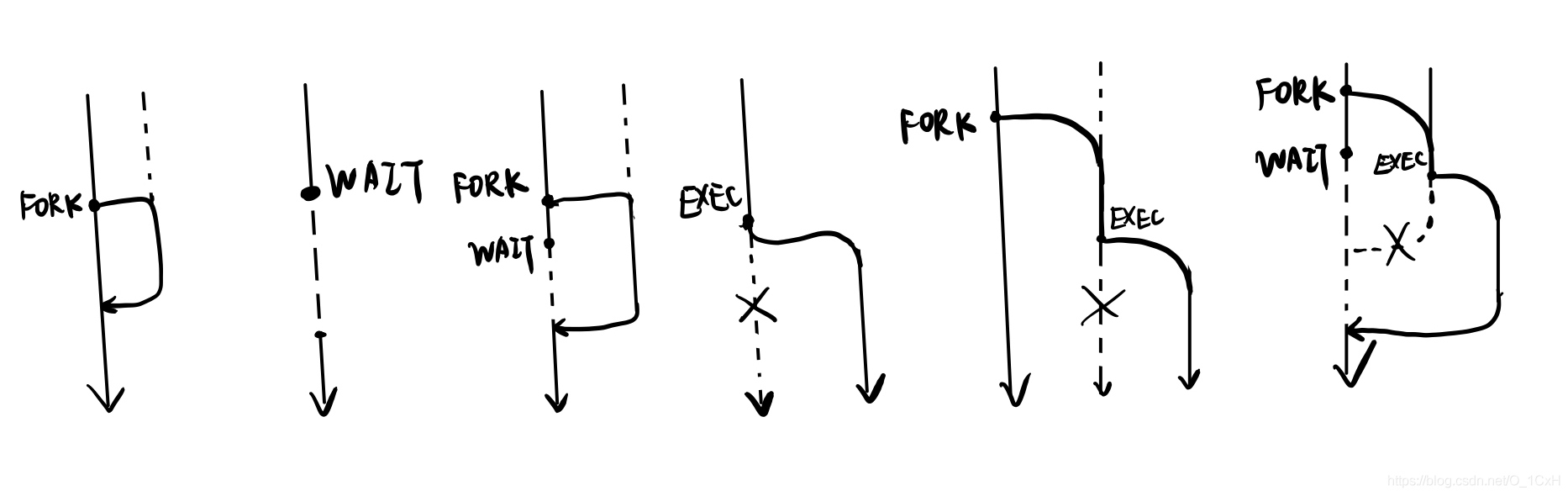
4.2 进程如何执行
4.2.1 策略:直接执行(Library OS Model)
直接在硬件上执行进程,而操作系统则充当一个库,对进程的要求做出服务:这就是Library OS的模型。当程序运行,操作系统将其载入内存成为进程,然后将PC寄存器改为main入口点的地址,然后程序就开始执行直到返回。
这样的做法存在一定的问题:如果进程出现错误一直不返回,或是恶意的进程执行危险的操作,或者进程长时间占用CPU导致其他进程无法运行,这样的情况下,library OS对其束手无策。因此这个策略只能在程序互信的环境下使用(例如某些实时操作系统)。
因此需要解决两个问题:(1)限制进程可以执行的指令、(2)(抢占式OS)操作系统强制获得CPU控制权。
4.2.2 策略:受限直接执行(Sleep Beauty Model)
操作系统的睡美人模型(Sleep Beauty Model)认为操作系统是一个事件处理器(event handler),平常都处在沉睡之中,直到有事件(event)发生的时候才将被唤醒,来按照一定规则处理这些事件。这种策略体现了操作系统设计中的隔离性(isolation)。所有的“事件”按属性被分为如下4种:
| Unexpected | Delibrate | |
|---|---|---|
| Synchronous(进程等待CPU完成处理才能继续) | Fault / Exception(执行指令时的错误),例如Page fault | System call / Trap(由用户发起),例如fork |
| Asynchronous (进程无需等待可以直接继续) | Interrupt(来自外部设备),例如键盘输入 | Signal,例如进程间通信 |
操作系统应当对所有的四类事件都有解决方案,这体现在IVT(interrupt vector table)中。当事件发生,操作系统跳停下当前用户进程,转到内核模式(称为陷入,trap),并在IVT中寻找对应处理方案(handler)程序的入口地址,然后跳转。当然,预先制作所有情况下的handler是不可能的,因而操作系统也会出现内核错误(kernel panic),表现为蓝屏或死机。
针对直接执行面临的两个问题,使用Sleep Beauty Model如此解决:
- 限制进程可以执行的指令 为了区别对待普通的指令和敏感指令,现代操作系统基本都引入了用户和内核两种模式。进程一般在用户模式下运行(只能执行普通指令),当需要执行敏感指令的时候则跳转到内核模式(一般通过system call / trap),因此这种模式叫做受限直接执行(LDE)。
- 抢占式操作系统中强制回收控制权 在非抢占式OS中,进程不会主动放弃CPU。现代主流的一般目的(general purpose)操作系统则一般是抢占式的,操作系统会在一定条件下强制收回CPU控制权,以免单个进程占用过长时间,这也是time sharing系统的关键。具体的方法是使用时钟中断(timer interrupt),时钟硬件定时发送一个中断(例如几毫秒一次),操作系统则会停下当前进程,进入内核模式,处理该中断,而收回控制权。
4.2.3 如何切换
受限直接执行策略的trap过程中,需要使用到某种切换机制:无论是从用户进程跳转到内核,还是反过来(进程之间的切换是通过进程A-内核-进程B的方式完成的),都要保证回到进程的时候进程正确地回到之前运行的位置。这种切换机制就是上下文切换(context switch),具体的做法如下:
(1)事件产生 (2)将当前用户进程的寄存器压入该进程的内核栈 (3)修改mode register(其中存储hardware status)为内核态 (4)查找IVT,找到对应的handler入口 (5)执行handler (6)从用户进程的内核栈恢复寄存器 (7)恢复mode register为用户态 (8)执行用户进程
值得一提的是在该书6.3节中的示例(如图)。
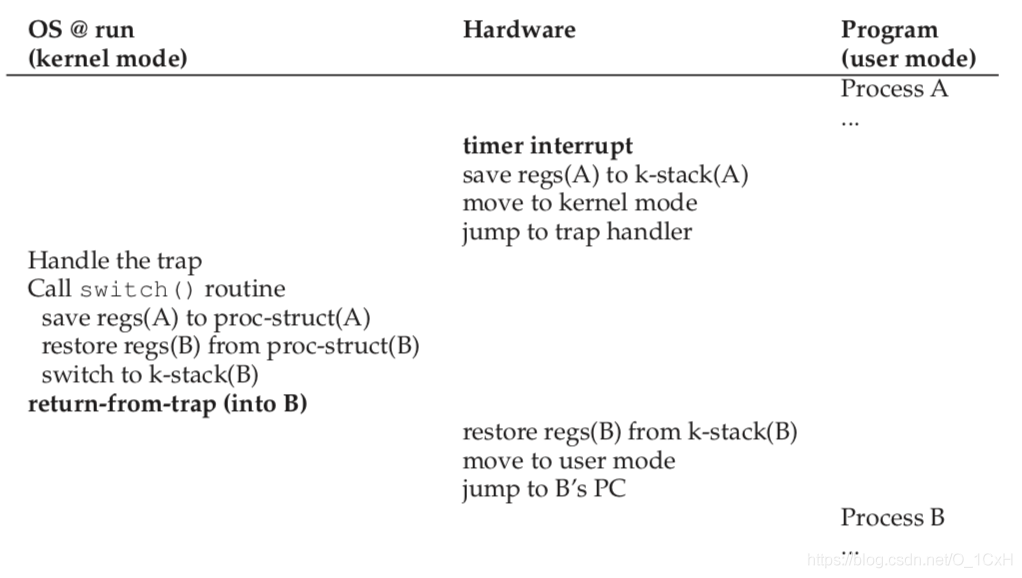
前面文字部分展示的上下文切换过程(将当前用户进程的寄存器压入该进程的内核栈,操作完成后从栈恢复到寄存器)是由硬件隐式完成的,在进程调度式发生类似的过程(从进程A切换到进程B,内核先保存A的寄存器到A的PCB,然后从B的PCB中恢复寄存器)则是在软件层面显式完成的。
二者的区别在于(1)硬件的上下文切换针对当前正在运行的进程,在发生中断时自动进行,保证中断前后的一致;软件的上下文切换针对整体调度,保证调度前后的一致性(2)软件层面的切换将上下文保存到PCB中,硬件则是保存在内存栈中。
4.3 进程调度
进程调度,顾名思义就是内核如何安排接下来要运行的进程。一般来说,在时钟中断的时候,或者某进程因为缺少资源而进入内核的时候,内核会安排进程调度程序来选择退出内核态的时候接下来运行的进程。进程调度的底层机制就是上下文切换。
进程调度的评价指标包括周转时间(turnaround time)和响应时间(response time)。周转时间是性能指标,评价一个任务从到达到完成的耗时;响应时间是公平性指标,评价一个任务从到达到开始执行的耗时。
4.3.1 进程调度策略的发展线索
| 策略 | 内容 | 演化 | 缺点 |
|---|---|---|---|
| FIFO | 先到达的任务先执行 | 最符合直觉的策略 | 先到达的长任务让后到达的短任务饿死 |
| SJF (1954) | 最短的任务先执行 | 比FIFO优化了周转时间 | 任务会随时到达,而在长任务执行时到达的短任务饿死 |
| STCF | 能够以最短完成时间可以抢占其他任务 | 比SJF增加了抢占机制 | 无法确定任务的完成时间 |
| Round Robin | 所有进程轮番使用时间片 | 优化了响应时间 | 并不是所有的程序都能用完整个时间片,例如IO密集任务 |
| (重叠式)RR | 需要IO的任务让出时间片并在完成前不参与调度 | 比RR多了对IO考虑 | 周转时间差于SJF(但总体来说是有效的) |
| MLFQ (1962) | (见4.3.2) | 在没有任务长短的先验知识下,同时优化了周转时间和响应时间 | 稍显复杂(但被Windows、MacOS和Unix系统采用) |
| Lottery (1994) | 给每个进程分发一定量的彩票,每次调度时随机抽出一个号码,被抽中的进程获得CPU | 在给定优先级的环境下优化了公平性 | 只能在互信环境中使用,需要提前给定彩票数 |
| Stride (1995) | 给每个进程分发一定量的彩票,按彩票数的倒数计算步长,程序被调度一次则累计一次步长值,每次调度已经走过步长值最小的那一个 | 在给定优先级的环境下到达绝对公平,比Lottery优化了确定性 | 只能在互信环境中使用,需要提前给定彩票数 |
| CFS (2007) | (见4.3.3) | 在给定优先级的情况下保持绝对公平,比Stride拥有更多细节 | 稍显复杂(但是提出后迅速被Linux系统采用) |
4.3.2 Unix的策略:MLFQ
多级反馈队列(multi-level feedback queue)在没有关于任务时间的先验知识(prior knowledge)的情况下,同时要降低响应时间和周转时间。现今的Windows系统使用的就是优化后的MLFQ调度方式。 MLFQ包含许多队列,每个队列代表一个优先级(例如Windows有32个优先级)并且对应一个时间配额(time allotment,一般来说高优先级队列的配额低);进程在这些队列中,并且拥有一个记录其剩余时间配额的“账户”,首次进入一个队列时“账户”的值被设置为该队列的时间配额值。MLFQ调度遵循如下规则:
- 当新进程到达的时候(假定该进程完成时间短),将其加入最高优先级的队列;
- 调度的时候会选择优先级最高的非空队列,并将该队列中的进程轮转(RR)运行;
- 当一个进程被调度后,对该进程的运行时间计时,并在该进程的“账户”中减去对应时长;
- 当一个进程的“账户”归零(即用完了该层的时间配额)的时候,进入下一级队列;
- 定期将所有进程提升至最高优先级队列。
注:调度的单位实际上是调度实体,这里简化称为进程。
4.3.3 Linux的策略:CFS
CFS(completely fair scheduler)中,每个进程: (1)拥有一个nice值,与优先级相关,从-20到+19,值越小越优先,默认为0;根据nice值可以计算出进程权重,权重越大越优先,计算方法为weight = 1024 / (1.25^nice); (2)拥有一个记录标准化CPU使用时间变量vruntime(virtual runtime,类似于stride调度中的pass属性) ,该值等于实际使用CPU的时间1024/进程权重,也就等于实际使用CPU的时间(1.25^nice);简单来说,vruntime是记录该进程使用CPU的“电表”,初始值为0。
CFS规定了一个调度周期(schedule latency),在一个调度周期内,所有可被调度的进程都被调度一次,而且所有进程的实际使用CPU的时间严格按照进程权重分配;换句话说,所有进程经历的vruntime相同(即在一个调度周期内获得的虚拟时间片长度相同),都等于调度周期/进程数量。现今的Linux系统使用的就是CFS,该方法出现后立即代替了Linux之前的O(1)调度。CFS按如下规则运行:
- 调度时选择当前进程中vruntime最小的运行;
- 当一个进程被调度后,vruntime按照其实际使用的时间更新(将运行时间计入“账户”);
- 当新进程加入的时候,该进程的初始值会以当前所有vruntime中的最小值min_vruntime为基准来设置(而不是直接设置为0,否则会让新进程长时间占用CPU);
此外,还有一些补充说明:
- 如果当前系统中的进程过多,导致每个虚拟时间片太短(从而导致上下文切换开销太大),那么每个虚拟时间片应该提高(具体做法是,如果虚拟时间片小于sched_min_granularity_ns,则设置为sched_min_granularity_ns,同时调度周期应该按照新的虚拟时间片重新计算,即进程数量*sched_min_granularity_ns);
- 当新进程加入的时候,起初是值先是设置为min_vruntime,如果START_DEBIT被设置为1,那么会在min_vruntime上额外增加一定值推迟其运行;
- 就绪的进程信息存储在红黑树中(按vruntime值插入树),这样的树每个CPU核心拥有一个(每个核心单独调度),在寻找当前vruntime最小的进程时即搜索了红黑树,时间复杂度为O(logN)。
更新日志
392a5-于