ELK和kafka构建高并发分布式日志收集系统
ELK和kafka构建高并发分布式日志收集系统
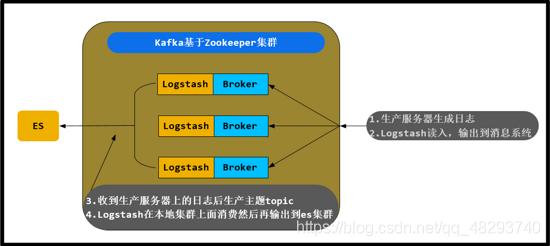
ELK+Kafka集群
前言
前言
业务层可以直接写入到kafka队列中,不用担心elasticsearch的写入效率问题。 图示
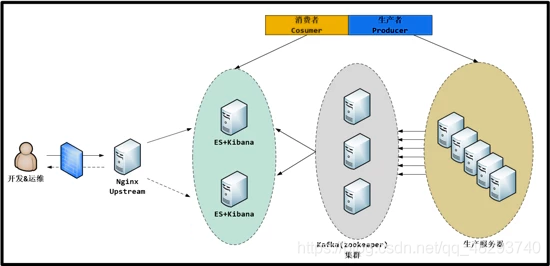
Kafka
Apache kafka是消息中间件的一种,是一种分布式的,基于发布/订阅的消息系统。能实现一个为处理实时数据提供一个统一、高吞吐、低延迟的平台,且拥有分布式的,可划分的,冗余备份的持久性的日志服务等特点。
术语
1、kafka是一个消息队列服务器。kafka服务称为broker(中间人), 消息发送者称为producer(生产者), 消息接收者称为consumer(消费者);通常我们部署多个broker以提供高可用性的消息服务集群.典型的是3个broker;消息以topic的形式发送到broker,消费者订阅topic,实现按需取用的消费模式;创建topic需要指定replication-factor(复制数目, 通常=broker数目);每个topic可能有多个分区(partition), 每个分区的消息内容不会重复
2、kafka-broker-中间人
3、webserver/logstash-producer[prəˈdu:sə®]-消息生产者/消息发送者
Producer:
kafka集群中的任何一个broker都可以向producer提供metadata信息,这些metadata中包含"集群中存活的servers列表"/“partitions leader列表"等信息;
当producer获取到metadata信息之后, producer将会和Topic下所有partition leader保持socket连接;
消息由producer直接通过socket发送到broker,中间不会经过任何"路由层”,事实上,消息被路由到哪个partition上由producer客户端决定;比如可以采用"random"“key-hash”"轮询"等,如果一个topic中有多个partitions,那么在producer端实现"消息均衡分发"是必要的。
在producer端的配置文件中,开发者可以指定partition路由的方式。
Producer消息发送的应答机制设置发送数据是否需要服务端的反馈,有三个值0,1,-1
0:producer不会等待broker发送ack
1:当leader接收到消息之后发送ack
-1:当所有的follower都同步消息成功后发送ack
4、elasticsearch-consumer-消费者
5、logs-topic-话题
6、replication-facter-复制数目-中间人存储消息的副本数=broker数目
7、一个topic有多个分区partition
partition:
(1)、Partition:为了实现扩展性,一个非常大的topic可以分布到多个broker(即服务器)上,一个topic可以分为多个partition,每个partition是一个有序的队列。partition中的每条消息都会被分配一个有序的id(offset)。kafka只保证按一个partition中的顺序将消息发给consumer,不保证一个topic的整体(多个partition间)的顺序。
(2)、在kafka中,一个partition中的消息只会被group中的一个consumer消费(同一时刻);一个Topic中的每个partions,只会被一个consumer消费,不过一个consumer可以同时消费多个partitions中的消息。实战
拓扑
说明
说明
1、使用一台Nginx代理访问kibana的请求;
2、两台es组成es集群,并且在两台es上面都安装kibana;( 以下对elasticsearch简称es )
3、中间三台服务器就是我的kafka(zookeeper)集群啦; 上面写的 消费者/生产者 这是kafka(zookeeper)中的概念;
4、最后面的就是一大堆的生产服务器啦,上面使用的是logstash,
当然除了logstash也可以使用其他的工具来收集你的应用程序的日志,例如:Flume,Scribe,Rsyslog,Scripts……角色
1、nginx-proxy(略):172.16.100.25
2、es1:172.16.100.21
3、es2:172.16.100.24
4、kafka1:172.16.100.26
5、kafka2:172.16.100.27
6、kafka3:172.16.100.32
7、webserver:172.16.100.33软件说明
1、elasticsearch - 1.7.3.tar.gz
2、Logstash - 2.0.0.tar.gz
3、kibana - 4.1.2 - linux - x64 . tar . gz(略):
以上软件都可以从官网下载 : https : //www.elastic.co/downloads
4、java - 1.8.0 , nginx 采用 yum 安装步骤
1、ES集群安装配置;
2、Logstash客户端配置(直接写入数据到ES集群,写入系统messages日志);
3、Kafka(zookeeper)集群配置;(Logstash写入数据到Kafka消息系统);
4、Kibana部署;
5、Nginx负载均衡Kibana请求;演示
1、ES集群安装配置
es1: (1)、安装java-1.8.0以及依赖包(每台服务器都安装JAVA)
# yum -y install epel-release
# yum -y install java-1.8.0 git wget lrzsz
#缓存这个java的包
#可以使用只下载不安装,缓存这些包
# yum -y install java-1.8.0 git wget lrzsz --downloadonly --downloaddir=./
#注释: --downloadonly 只下载不安装 downloaddir 目录(2)、获取es软件包
# wget https://download.elastic.co/elasticsearch/elasticsearch/elasticsearch-1.7.3.tar.gz
# tar -xf elasticsearch-1.7.3.tar.gz -C /usr/local/
# ln -sv /usr/local/elasticsearch-1.7.3/ /usr/local/elasticsearch(3)、修改配置文件
# vim /usr/local/elasticsearch/config/elasticsearch.yml
cluster.name: es-cluster #组播的名称地址
node.name: "es-node1" #节点名称,不能和其他节点重复
node.master: true #节点能否被选举为master
node.data: true #节点是否存储数据
index.number_of_shards: 5 #索引分片的个数
index.number_of_replicas: 1 #分片的副本个数
path.conf: /usr/local/elasticsearch/config #配置文件的路径
path.data: /data/es/data #数据目录路径
path.work: /data/es/worker #工作目录路径
path.logs: /usr/local/elasticsearch/logs #日志文件路径
path.plugins: /data/es/plugins #插件路径
bootstrap.mlockall: true #内存不向swap交换
http.enabled: true #启用http(4)、创建相关目录
# mkdir -p /data/es/{data,worker,plugins}
#注释:data:放数据的文件 worker:工作临时文件 plugins:插件 日志文件会自己建立(5)、获取es服务管理脚本
#为了方便配置文件
# git clone https://github.com/elastic/elasticsearch-servicewrapper.git
# mv elasticsearch-servicewrapper/service/ /usr/local/elasticsearch/bin/
#在/etc/init.d/目录下,自动安装上es的管理脚本啦
# /usr/local/elasticsearch/bin/service/elasticsearch install(6)、启动es,并检查服务是否正常
# systemctl start elasticsearch
# systemctl enable elasticsearch
# ss -nptl |grep -E "9200|9300"
LISTEN 0 50 :::9200 :::* users:(("java",pid=10020,fd=104))
LISTEN 0 50 :::9300 :::* users:(("java",pid=10020,fd=66))访问192.168.88.153:9200

(3)、安装es的管理插件 (1)、说明:es官方提供一个用于管理es的插件,可清晰直观看到es集群的状态,以及对集群的操作管理,安装方法如下: (2)、提示:
# /usr/local/elasticsearch/bin/plugin -i mobz/elasticsearch-head安装好之后,访问方式为: http://192.168.0.110:9200/_plugin/head, 由于集群中现在暂时没有数据,所以显示为空, 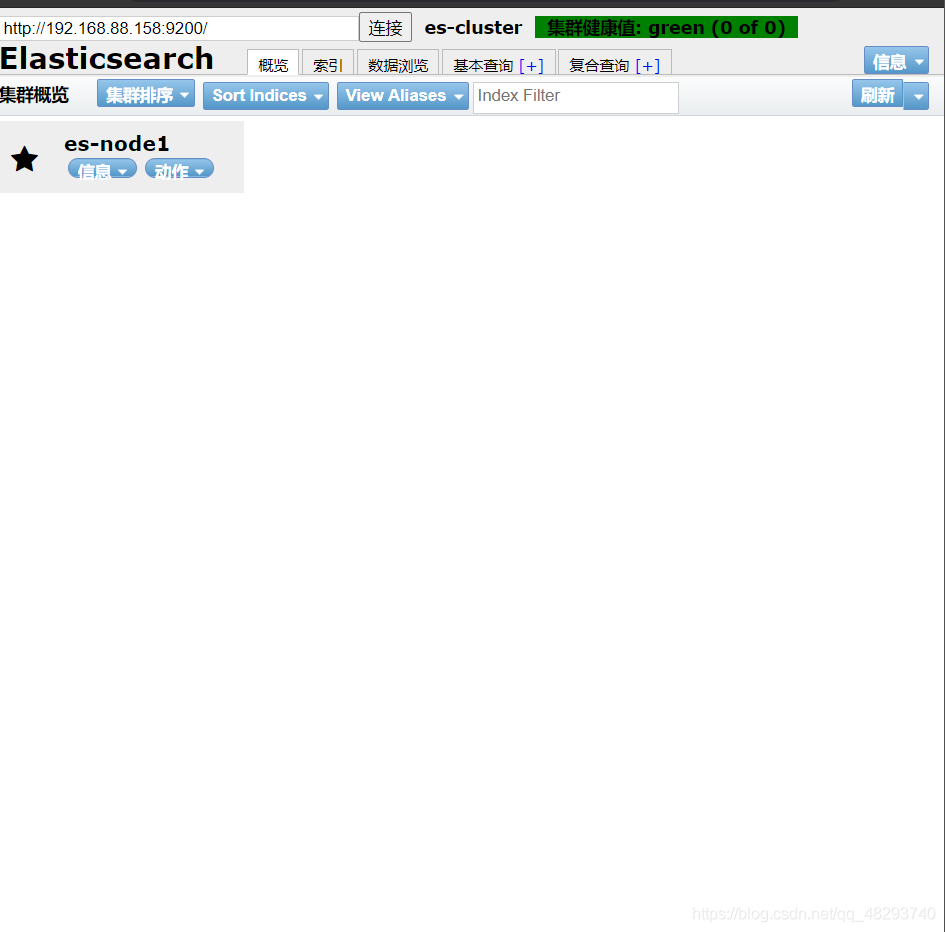
2、Logstash客户端安装配置(在webserver1上安装logstassh,用于采集日志)
(1)、downloads 软件包
# yum -y install java-1.8.0
# wget https://download.elastic.co/logstash/logstash/logstash-2.0.0.tar.gz
# tar -xf logstash-2.0.0.tar.gz -C /usr/local
# cd /usr/local/
# ln -sv logstash-2.0.0 logstash
# mkdir /usr/local/logstash/{logs,etc}(2)、Logstash 向es集群写数据 编写配置文件;
# vim /usr/local/logstash/etc/logstash.conf
input { #数据的输入从标准输入
stdin { }
}
output { #数据的输出我们指向了es集群
elasticsearch {
hosts => [ "192.168.0.110:9200" , "192.168.0.111:9200" ] #es 主机的 ip 及端口
}
}检查配置文件是否有语法错误:
# /usr/local/logstash/bin/logstash -f /usr/local/logstash/etc/logstash.conf --configtest --verbose
输出提示:
Configuration OK 语法正确(3)、启动logstash 启动;
# /usr/local/logstash/bin/logstash -f /usr/local/logstash/etc/logstash.conf3、Kafka集群安装配置
(1)、提示:在搭建kafka集群时,需要提前安装zookeeper集群,当然kafka已经自带zookeeper程序只需要解压并且安装配置就行了 (2)、Kafka1 获取软件包:
官网: http://kafka.apache.org
# yum install -y java-1.8.0
# wget http://mirror.rise.ph/apache/kafka/0.8.2.1/kafka_2.11-0.8.2.1.tgz
http://mirror.rise.ph/apache/kafka/2.6.2/kafka_2.12-2.6.2.tgz
# tar -xf kafka_2.12-2.6.2.tgz -C /usr/local/
# cd /usr/local/
# ln -sv kafka_2.12-2.6.2 kafka配置zookeeper集群:
# vim /usr/local/kafka/config/zookeeper.properties
dataDir=/data/zookeeper
clientPort=2181
tickTime=2000
#注释:tickTime : 这个时间是作为 Zookeeper 服务器之间或客户端与服务器之间维持心跳的时间间隔,也就是每个 tickTime 时间就会发送一个心跳。
initLimit=20
#注释:initLimit:LF初始通信时限
#集群中的follower服务器(F)与leader服务器(L)之间 初始连接 时能容忍的最多心跳数(tickTime的数量)。
#此配置表示,允许 follower (相对于 leader 而言的“客户端”)连接 并同步到 leader 的初始化连接时间,它以 tickTime 的倍数来表示。当超过设置倍数的 tickTime 时间,则连接失败
syncLimit=10
#注释:syncLimit:LF同步通信时限
#集群中的follower服务器(F)与leader服务器(L)之间 请求和应答 之间能容忍的最多心跳数(tickTime的数量)。
#此配置表示, leader 与 follower 之间发送消息,请求 和 应答 时间长度。如果 follower 在设置的时间内不能与leader 进行通信,那么此 follower 将被丢弃。
server.2=192.168.0.112:2888:3888
#注释:
#2888 端口:表示的是这个服务器与集群中的 Leader 服务器交换信息的端口;
#3888 端口:表示的是万一集群中的 Leader 服务器挂了,需要一个端口来重新进行选举,选出一个新的 Leader ,而这个端口就是用来执行选举时服务器相互通信的端口。
server.3=192.168.0.113:2888:3888
server.4=192.168.0.115:2888:3888
maxClientCnxns=0
#注释:
#maxClientCnxns选项,如果不设置或者设置为0,则每个ip连接zookeeper时的连接数没有限制创建zookeeper所需要的目录:
# mkdir /data/zookeeper创建myid文件:
#在/data/zookeeper目录下创建myid文件,里面的内容为数字,用于标识主机,如果这个文件没有的话,zookeeper是没法启动的
# echo 2 > /data/zookeeper/myid
#另外两台,分别是3,4。以上就是zookeeper集群的配置,下面等我配置好kafka之后直接复制到其他两个节点即可Kafka配置:
# vim /usr/local/kafka/config/server.properties
broker.id=2
#注释:唯一,填数字,本文中分别为 2 / 3 / 4
prot=9092
#注释:这个 broker 监听的端口
host.name=192.168.0.112
#注释:唯一,填服务器 IP
log.dir=/data/kafka-logs
#注释:该目录可以不用提前创建,在启动时自己会创建
zookeeper.connect=192.168.0.112:2181,192.168.0.113:2181,192.168.0.115:2181
#注释:这个就是 zookeeper 的 ip 及端口
num.partitions=16
#注释:需要配置较大 分片影响读写速度
log.dirs=/data/kafka-logs
#注释:数据目录也要单独配置磁盘较大的地方
log.retention.hours=168
#注释:时间按需求保留过期时间 避免磁盘满
#日志保存的时间,可以选择hours,minutes和ms 168(7day)(3)、Kafka3&Kafka3 将Kafka(zookeeper)的程序目录全部拷贝到其他两个节点:
# scp -r /usr/local/kafka 192.168.0.113:/usr/local/
# scp -r /usr/local/kafka 192.168.0.115:/usr/local/修改两个节点配置(这里基本相同,但是注意不同位置):
( 1 ) zookeeper 的配置
#kafka2和kafka3
# mkdir /data/zookeeper -p
# echo "x" > /data/zookeeper/myid #x为3或4
( 2 ) kafka 的配置
#kafka2和kafka3
# vim /usr/local/kafka/config/server.properties
broker.id=x #x为3或4
host.name=192.168.x.xx #x为Kafka2和Kafka3的ip启动,先启动zookeeper集群,才能启动Kafka
8.启动,先启动zookeeper集群,才能启动kafka
#提示:按照顺序来,kafka1 –> kafka2 –>kafka3
#zookeeper启动命令:
# /usr/local/kafka/bin/zookeeper-server-start.sh /usr/local/kafka/config/zookeeper.properties &
# /usr/local/kafka/bin/zookeeper-server-start.sh /usr/local/kafka/config/zookeeper.properties &
# /usr/local/kafka/bin/zookeeper-server-start.sh /usr/local/kafka/config/zookeeper.properties &
#注释:/usr/local/kafka/bin/zookeeper-server-stop.sh #zookeeper停止的命令
#如果zookeeper有问题 nohup的日志文件会非常大,把磁盘占满,
#这个zookeeper服务可以通过自己些服务脚本来管理服务的启动与关闭。
#后面两台执行相同操作,在启动过程当中会出现以下报错信息:
#WARN Cannot open channel to 3 at election address / 192.168.0.113 : 3888
#由于zookeeper集群在启动的时候,每个结点都试图去连接集群中的其它结点,先启动的肯定连不上后面还没启动的,所以上面日志前面部分的异常是可以忽略的。通过后面部分可以看到,集群在选出一个Leader后,最后稳定了。
#其他节点也可能会出现类似的情况,属于正常。zookeeper服务检查:
# netstat -nlpt | grep -E "2181|2888|3888"
#输出提示:
tcp6 0 0 192.168.0.112:3888 :::* LISTEN 1722/java
tcp6 0 0 :::2181 :::* LISTEN 1722/java
# netstat -nlpt | grep -E "2181|2888|3888"
#输出提示
tcp6 0 0 192.168.0.113:3888 :::* LISTEN 1713/java
tcp6 0 0 :::2181 :::* LISTEN 1713/java
tcp6 0 0 192.168.0.113:2888 :::* LISTEN 1713/java
#如果哪台是Leader,那么它就拥有2888这个端口
# netstat -nlpt | grep -E "2181|2888|3888"
#输出提示
tcp6 0 0 192.168.0.115:3888 :::* LISTEN 1271/java
tcp6 0 0 :::2181 :::* LISTEN 1271/java验证、启动Kafka:
#启动(在三台Kafka服务器上):
# nohup /usr/local/kafka/bin/kafka-server-start.sh /usr/local/kafka/config/server.properties &
# nohup /usr/local/kafka/bin/kafka-server-start.sh /usr/local/kafka/config/server.properties &
# nohup /usr/local/kafka/bin/kafka-server-start.sh /usr/local/kafka/config/server.properties &
#注释:/usr/local/kafka/bin/kafka-server-stop.sh #kafka停止的命令
#跟zookeeper服务一样,如果kafka有问题 nohup的日志文件会非常大,把磁盘占满,这个kafka服务同样可以通过自己些服务脚本来管理服务的启动与关闭。
#测试:
#下面我们将webserver1上面的logstash的输出改到kafka上面
(1)修改webserver1上面的logstash配置
# vim /usr/local/logstash/etc/logstash3.conf
input {
file {
type => "system-message"
path => "/var/log/messages"
start_position => "beginning"
}
}
output {
kafka {
bootstrap_servers => "192.168.0.112:9092,192.168.0.113:9092,192.168.0.115:9092"
topic_id => "system-messages" #这个将作为主题的名称,将会自动创建
compression_type => "snappy" #压缩类型
}
}
(2)配置检测
# /usr/local/logstash/bin/logstash -f /usr/local/logstash/etc/logstash3.conf --configtest --verbose
#输出提示:
Configuration OK
(3)启动Logstash
# /usr/local/logstash/bin/logstash -f /usr/local/logstash/etc/logstash3.conf
(4)验证数据是否写入到kafka,检查是否生成一个system-messages的主题
# /usr/local/kafka/bin/kafka-topics.sh --list --zookeeper 172.16.100.26:2181
#输出信息
summer
system - messages #可以看到这个主题已经生成了
(5)查看system-messages主题的详情
# /usr/local/kafka/bin/kafka-topics.sh --describe --zookeeper 172.16.100.26:2181 --topic system-message输出信息:
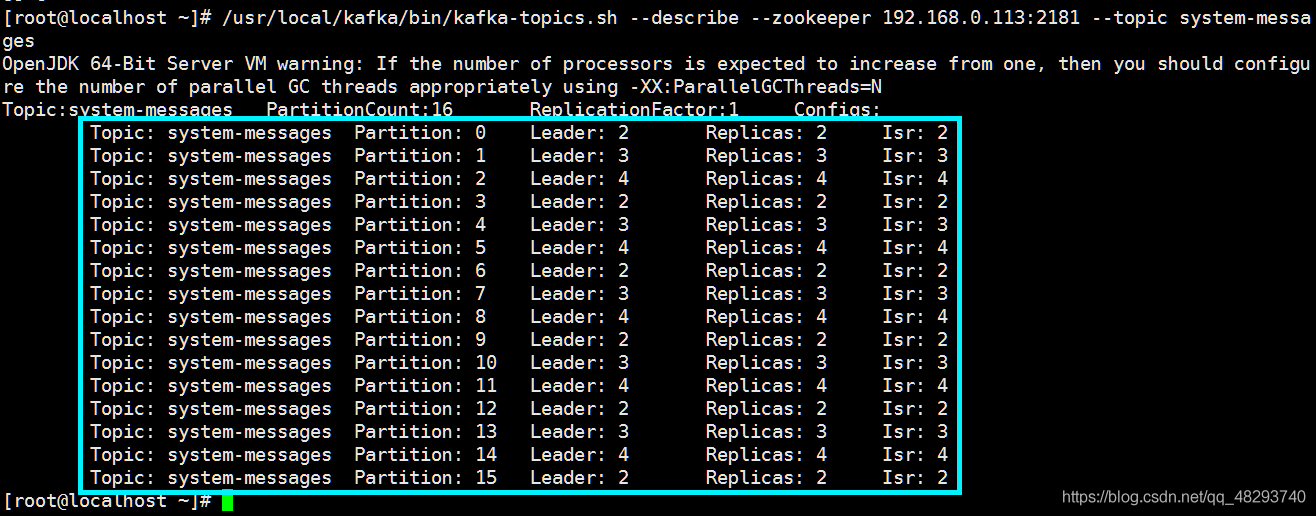
可以看出,这个主题生成了16个分区,每个分区都有对应自己的Leader
扩展提示: 我想要有10个分区,3个副本如何办?还是跟我们上面一样命令行来创建主题就行, 当然对于logstash输出的我们也可以提前先定义主题,然后启动logstash 直接往定义好的主题写数据就行啦,命令如下:
# /usr/local/kafka/bin/kafka-topics.sh --create --zookeeper 192.168.2.22:2181 --replication-factor 3 --partitions 10 --topic TOPIC_NAMEKafka集群部署logstash:
1、kafka 1&2&3安装logstash:
# wget https://download.elastic.co/logstash/logstash/logstash-2.0.0.tar.gz
# tar -xf logstash-2.0.0.tar.gz -C /usr/local
# cd /usr/local/
# ln -sv logstash-2.0.0 logstash
# mkdir /usr/local/logstash/{logs,etc}
2、三台kafak编写logstash配置文件
# vim /usr/local/logstash/etc/logstash.conf
#2181后面不能有空格
#decorate_events => true:此属性会将当前topic、offset、group、partition等信息也带到message中
input {
kafka {
zk_connect => "172.16.100.26:2181,172.16.100.27:2181,172.16.100.32:2181" #消费者们
topic_id => "system-message"
codec => plain
reset_beginning => false
consumer_threads => 5
decorate_events => true
}
}
output {
elasticsearch {
hosts => ["172.16.100.21:9200","172.16.100.24:9200"]
index => "test-system-messages-%{+YYYY-MM}" #区分之前实验,新名字“test-system-messages-%{+YYYY-MM}”
}
}
3、webserver1上写入测试内容
# echo "00000">/var/log/messages
# echo "我将通过kafka集群达到es集群1234" >> /var/log/messages
# /usr/local/logstash/bin/logstash -f /usr/local/logstash/etc/logstash3.conf
4、三台kafka启动logstash(注意顺序1>2>3)
# /usr/local/logstash/bin/logstash -f /usr/local/logstash/etc/logstash.conf
# /usr/local/logstash/bin/logstash -f /usr/local/logstash/etc/logstash.conf
# /usr/local/logstash/bin/logstash -f /usr/local/logstash/etc/logstash.conf查看es管理界面:
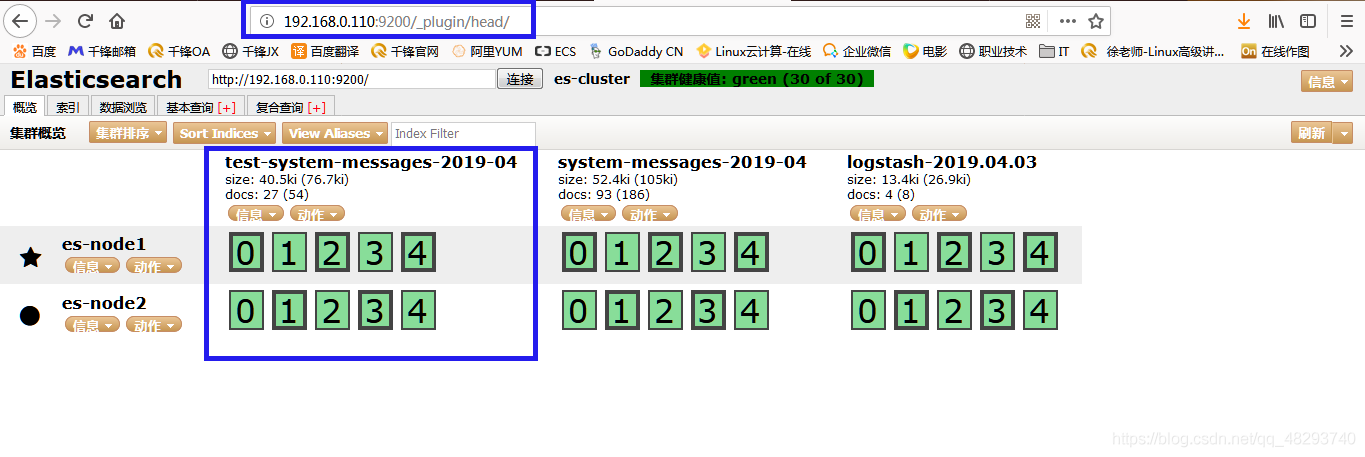
总结
4、扩展(Nginx负载均衡Kibana的请求)
(1)、在nginx-proxy上面yum安装nginx
# yum install -y nignx(2)、编写配置问佳佳es.conf
# vim /etc/nginx/conf.d/es.conf
upstream es {
server 172.16.100.21:5601 max_fails=3 fail_timeout=30s;
server 172.16.100.24:5601 max_fails=3 fail_timeout=30s;
}
server {
listen 80;
server_name localhost;
location / {
proxy_pass http://es/;
index index.html index.htm;
#auth
auth_basic "ELK Private";
auth_basic_user_file /etc/nginx/.htpasswd;
}
}(3)、创建认证
3.创建认证
# htpasswd -cm /etc/nginx/.htpasswd elk
New password:
Re-type new password:
Adding password for user elk-user
# /etc/init.d/nginx restart
Stopping nginx: [ OK ]
Starting nginx: [ OK ](4)、访问
1、解耦
允许你独立的扩展或修改两边的处理过程,只要确保它们遵守同样的接口约束
2、冗余
消息队列把数据进行持久化直到它们已经被完全处理,通过这一方式规避了数据丢失风险。许多消息队列所采用的"插入-获取-删除"范式中,在把一个消息从队列中删除之前,需要你的处理系统明确的指出该消息已经被处理完毕,从而确保你的数据被安全的保存直到你使用完毕。
3、扩展性
因为消息队列解耦了你的处理过程,所以增大消息入队和处理的频率是很容易的,只要另外增加处理过程即可。
4、灵活性 & 峰值处理能力
在访问量剧增的情况下,应用仍然需要继续发挥作用,但是这样的突发流量并不常见。 如果为以能处理这类峰值访问为标准来投入资源随时待命无疑是巨大的浪费。使用消息队列能够使关键组件顶住突发的访问压力,而不会因为突发的超负荷的请求而完全崩溃。
5、可恢复性
系统的一部分组件失效时,不会影响到整个系统。 消息队列降低了进程间的耦合度,所以即使一个处理消息的进程挂掉,加入队列中的消息仍然可以在系统恢复后被处理。
6、顺序保证
在大多使用场景下,数据处理的顺序都很重要。
大部分消息队列本来就是排序的,并且能保证数据会按照特定的顺序来处理。(Kafka 保证一个 Partition 内的消息的有序性) 7、缓冲
有助于控制和优化数据流经过系统的速度,解决生产消息和消费消息的处理速度不一致的情况。
8、异步通信
很多时候,用户不想也不需要立即处理消息。 消息队列提供了异步处理机制,允许用户把一个消息放入队列,但并不立即处理它。想向队列中放入多少消息就放多少,然后在需要的时候再去处理它们。
Redis与Kafka
我们都知道Redis是以key的hash方式来分散对列存储数据的,且Redis作为集群使用时,对应的应用对应一个Redis,在某种程度上会造成数据的倾斜性,从而导致数据的丢失。
而从之前我们部署Kafka集群来看,kafka的一个topic(主题),可以有多个partition(副本),而且是均匀的分布在Kafka集群上,这就不会出现redis那样的数据倾斜性。Kafka同时也具备Redis的冗余机制,像Redis集群如果有一台机器宕掉是很有可能造成数据丢失,而Kafka因为是均匀的分布在集群主机上,即使宕掉一台机器,是不会影响使用。同时Kafka作为一个订阅消息系统,还具备每秒百万级别的高吞吐量,持久性的、分布式的特点等。
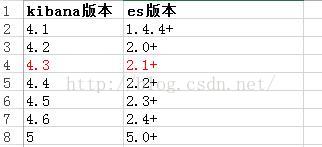
更新日志
60eca-于d6ac4-于b1df1-于392a5-于